Chapter 3 Models
In this section, we will:
- Combine the data across samples and create new data frames for each personality trait / well-being x covariate x outcome x moderator combination.
- As preregistered, we will then rescale variables in each sample to harmonize across samples
- Next, we will create a series of functions to:
- Run the model
- Extract sample-specific estimates from each sample
- Extract cross-sample heterogeneity estimates
- Extract fixed and and random simple slopes
- Run the models or export files to the computing cluster to speed up runtime.
3.1 Part 1: Combine Data
First, we’ll just load in all the combined data frames for each sample and keep our core variables:
loadRData <- function(fileName, type){
#loads an RData file, and returns it
path <- sprintf("%s/data/clean/%s_cleaned.RData", local_path, fileName)
load(path)
get(ls()[grepl(type, ls())])
}
# which(apply(nested_data %>% mutate(cols = map(data, colnames)) %>% select(-data) %>% unnest(cols) %>% mutate(inc = "yes") %>% spread(study, inc), 1, function(x){sum(is.na(x))/7*100}) < 25)
nested_data <- tibble(
study = studies
, data = map(str_to_lower(study), ~loadRData(., "combined"))
) %>%
mutate(
data = map(data, ~(.) %>%
ungroup() %>%
mutate(SID = as.character(SID)) %>%
select(SID, Trait, p_year, p_value, Outcome, o_year, o_value # core variables
, one_of(c("age", "gender", "education", "cognition"
, "alcohol", "smokes", "BMI", "race", "SRhealth"
, "stroke", "cancer", "diabetes", "heartProb", "dementia")))
)
, study = mapvalues(study, studies, studies_long)
) %>%
unnest(data) %>%
# removing this outcome because there was no variance for WUSM MAP
filter(!(Outcome == "vsclrInfrcts" & study == "ADRC"))
nested_data## # A tibble: 421,476 × 22
## study SID Trait p_year p_value Outcome o_year o_value age gender education cognition alcohol smokes
## <chr> <chr> <chr> <dbl> <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 ROS 000210… A 0 32 angiop… 2 3 80.0 0 22 4.19 0 0
## 2 ROS 000210… A 0 32 arteri… 2 0 80.0 0 22 4.19 0 0
## 3 ROS 000210… A 0 32 athero… 2 2 80.0 0 22 4.19 0 0
## 4 ROS 000210… A 0 32 braak 2 6 80.0 0 22 4.19 0 0
## 5 ROS 000210… A 0 32 cerad 2 1 80.0 0 22 4.19 0 0
## 6 ROS 000210… A 0 32 hipScl… 2 0 80.0 0 22 4.19 0 0
## 7 ROS 000210… A 0 32 lewyBo… 2 0 80.0 0 22 4.19 0 0
## 8 ROS 000210… A 0 32 vsclrI… 2 0 80.0 0 22 4.19 0 0
## 9 ROS 000210… A 0 32 vsclrM… 2 1 80.0 0 22 4.19 0 0
## 10 ROS 000210… A 0 32 tdp43 2 1 80.0 0 22 4.19 0 0
## # ℹ 421,466 more rows
## # ℹ 8 more variables: BMI <dbl>, race <dbl>, stroke <dbl>, cancer <dbl>, diabetes <dbl>, heartProb <dbl>,
## # dementia <dbl>, SRhealth <dbl>3.2 Part 2: Clean and Prepare Data Sets
Next time to rescale or relevel variables.
3.2.1 Descriptives
But first, we’ll make a table of descriptive values (M (SD) or percentage) for all variables for each sample.
cln <- c("Study", "E", "A", "C", "N", "O", "Crystallized / Knowledge", "Age (Years)", "Education (Years)", "% Women")
fctr_vars <- c("dementia", "hipSclerosis", "lewyBodyDis", "tdp43", "vsclrInfrcts", "vsclrMcrInfrcts", "gender"
, "smokes", "alcohol", "race", "stroke", "cancer", "diabetes", "heartProb")
transpose_df <- function(df) {
t_df <- data.table::transpose(df)
colnames(t_df) <- rownames(df)
rownames(t_df) <- colnames(df)
t_df <- t_df %>%
tibble::rownames_to_column(.data = .) %>%
tibble::as_tibble(.) %>%
filter(row_number() != 1) %>%
set_names(c("Variable", df$study))
return(t_df)
}
desc_tab <-
nested_data %>%
select(-p_year, -o_year, -one_of(fctr_vars)) %>%
group_by(study, Trait, Outcome) %>%
mutate_at(vars(p_value, SRhealth),
~((. - min(., na.rm = T))/(max(., na.rm = T) - min(., na.rm = T))*10)) %>%
mutate_at(vars(p_value, SRhealth), ~ifelse(is.infinite(.), NA, .)) %>%
ungroup() %>%
pivot_wider(names_from = Outcome, values_from = o_value, values_fn = mean) %>%
pivot_wider(names_from = Trait, values_from = p_value, values_fn = mean)
int_followup <- nested_data %>%
select(study, SID, Trait, Outcome, p_year, o_year) %>%
mutate(interval = o_year - p_year
, cat = ifelse(Outcome == "dementia", "dem_int", "neuro_int")) %>%
group_by(study, SID, Trait, cat) %>%
summarize(interval = mean(interval)) %>%
group_by(study, SID, cat) %>%
summarize(interval = mean(interval)) %>%
group_by(study, cat) %>%
summarize(int = sprintf("%.2f (%.2f)", mean(interval, na.rm = T), sd(interval, na.rm = T))) %>%
ungroup() %>%
pivot_wider(names_from = "cat", values_from = "int")
desc_tab <- desc_tab %>%
group_by(study) %>%
mutate(n = n()) %>%
ungroup() %>%
left_join(
desc_tab %>%
select(-dementia) %>%
filter(!is.na(braak) | !is.na(cerad) | !is.na(tdp43)) %>%
group_by(study) %>%
summarize(n_neuro = n()) %>%
ungroup()
) %>%
select(-one_of(fctr_vars)) %>%
distinct() %>%
pivot_longer(cols = c(-study, -SID, -n, -n_neuro), values_to = "value", names_to = "item", values_drop_na = T) %>%
group_by(study, item, n, n_neuro) %>%
summarize(est = sprintf("%.2f (%.2f)", mean(value, na.rm = T), sd(value, na.rm = T))) %>%
ungroup() %>%
pivot_wider(names_from = item, values_from = est) %>%
full_join(
nested_data %>%
group_by(Outcome, SID, study) %>%
filter(o_year == min(o_year)) %>%
ungroup() %>%
select(-o_year, -dementia) %>%
pivot_wider(names_from = Outcome, values_from = o_value, values_fn = mean) %>%
select(-Trait, -p_year, -p_value) %>%
distinct() %>%
select(study, SID, one_of(fctr_vars)) %>%
distinct() %>%
group_by(study) %>%
summarize_at(vars(-SID), ~ifelse(is.nan(mean(., na.rm = T)), "", sprintf("%i (%.2f%%)", sum(., na.rm = T), mean(., na.rm = T)*100))) %>%
# summarize_at(vars(-SID), ~mean(., na.rm = T)*100) %>%
# mutate_at(vars(-study), ~ifelse(is.nan(.) | is.na(.), "", sprintf("%.2f%%", .))) %>%
ungroup()
) %>%
full_join(int_followup) %>%
select(study, E, A, C, N, O, PA, `NA`, SWL, n, dementia, dem_int,
n_neuro, neuro_int, one_of(outcomes$short_name),
age, gender, education, cognition, BMI, SRhealth, smokes, alcohol,
BMI, race, stroke, cancer, diabetes, heartProb) %>%
transpose_df() %>%
mutate(Variable = mapvalues(Variable, c("n", "n_neuro", "dem_int", "neuro_int"), c("Valid Dementia N", "Valid Neuropathology N", "Mean Dementia Follow-up (Years)", "Mean Neuropathology Follow-up (Years)"))
, Variable = mapvalues(Variable, c(traits$short_name, outcomes$short_name), str_wrap(c(traits$long_name, outcomes$long_name), 25))) %>%
select(Variable, `Rush-MAP`, ROS, `WUSM-MAP`, EAS, GSOEP, HRS, LISS, SATSA) %>%
kable(., "html"
, digits = 2
# , col.names = cln
, caption = "<strong>Table 1</strong><br><em>Descriptive Statistics of All Harmonized Measures Across Samples"
, align = c("l", rep("c",9))) %>%
kable_classic(full_width = F, html_font = "Times New Roman") %>%
kableExtra::group_rows("Big Five Personality", 1, 5) %>%
kableExtra::group_rows("Subjective Well-Being", 6, 8) %>%
kableExtra::group_rows("Dementia", 9, 11) %>%
kableExtra::group_rows("Dementia and Neuropathology", 12, 23) %>%
kableExtra::group_rows("Covariates", 24, 36) %>%
add_footnote(notation = "none", label = "<em>Note.</em> E = Extraversion; A = Agreeableness; C = Conscientiousness; N = Neuroticism; O = Openness, PA = Positive Affect, NA = Negative Affect, SWL = Satisfaction with Life; Age, education, gender, smoking, alcohol, BMI, chronic conditions, and cognition were assessed at the first baseline personality assessment.", escape = F); desc_tab| Variable | Rush-MAP | ROS | WUSM-MAP | EAS | GSOEP | HRS | LISS | SATSA |
|---|---|---|---|---|---|---|---|---|
| Big Five Personality | ||||||||
| Extraversion | 5.50 (1.69) | 5.17 (1.65) | 5.73 (1.67) | 5.59 (1.75) | 6.40 (1.88) | 7.32 (1.86) | 5.64 (1.62) | 6.33 (0.74) |
| Agreeableness | 5.33 (1.40) | 6.37 (1.62) | 6.73 (1.87) | 7.45 (1.63) | 8.41 (1.60) | 6.68 (1.48) | 7.23 (1.17) | |
| Conscientiousness | 6.25 (1.57) | 6.27 (1.39) | 6.31 (1.79) | 6.95 (1.73) | 8.21 (1.55) | 7.84 (1.63) | 6.34 (1.49) | 7.05 (1.35) |
| Neuroticism | 3.65 (1.68) | 4.59 (1.61) | 3.94 (1.91) | 3.56 (2.08) | 4.92 (2.04) | 3.52 (2.06) | 3.97 (1.69) | 6.53 (1.35) |
| Openness to Experience | 5.50 (1.51) | 5.60 (1.59) | 5.85 (2.03) | 5.88 (2.01) | 6.43 (1.88) | 5.98 (1.34) | 4.84 (1.34) | |
| Subjective Well-Being | ||||||||
| Positive Affect | 8.46 (1.82) | 8.20 (3.86) | 6.22 (2.15) | 6.55 (1.94) | 5.94 (1.67) | 7.47 (2.12) | ||
| Negative Affect | 1.06 (1.30) | 3.63 (1.98) | 1.93 (1.82) | 1.75 (1.76) | 2.14 (2.29) | |||
| Satisfaction with Life | 7.39 (1.78) | 6.75 (2.20) | 7.00 (1.76) | 6.07 (2.34) | 6.56 (1.46) | 5.75 (2.87) | ||
| Dementia | ||||||||
| Valid Dementia N | 4283 | 3374 | 1478 | 813 | 31072 | 14167 | 6543 | 2002 |
| Incident Dementia Diagnosis | 444 (22.17%) | 428 (30.77%) | 232 (27.39%) | 44 (5.67%) | 180 (1.03%) | 1130 (7.98%) | 20 (0.31%) | 163 (8.14%) |
| Mean Dementia Follow-up (Years) | 5.48 (4.14) | 9.56 (6.61) | 15.59 (22.11) | 2.70 (2.92) | 11.20 (0.48) | 6.76 (2.26) | 5.19 (4.43) | 21.00 (0.00) |
| Dementia and Neuropathology | ||||||||
| Valid Neuropathology N | 1721 | 1525 | 627 | 37 | ||||
| Mean Neuropathology Follow-up (Years) | 6.16 (3.62) | 10.46 (6.04) | 14.83 (22.50) | 7.29 (3.52) | ||||
| Braak Stage | 3.77 (1.20) | 3.58 (1.25) | 4.01 (1.66) | 3.12 (1.06) | ||||
| CERAD | 2.16 (1.12) | 2.22 (1.13) | 2.46 (0.81) | |||||
| Lewy Body Disease | 177 (23.14%) | 177 (23.44%) | 58 (38.67%) | 4 (11.76%) | ||||
| Gross Cerebral Infarcts | 298 (37.91%) | 271 (34.70%) | 158 (100.00%) | |||||
| Gross Cerebral Microinfarcts | 260 (33.08%) | 245 (31.37%) | 27 (17.09%) | |||||
| Cerebral Atherosclerosis | 1.13 (0.77) | 1.24 (0.78) | 1.29 (0.76) | |||||
| Cerebral Amyloid Angiopathy | 1.29 (0.95) | 1.29 (0.97) | 1.27 (0.88) | |||||
| Arteriolosclerosis | 1.03 (0.91) | 0.99 (0.96) | 1.42 (0.70) | |||||
| Hippocampal Sclerosis | 69 (9.77%) | 56 (7.64%) | 3 (3.66%) | 4 (11.76%) | ||||
| TDP-43 | 428 (54.31%) | 353 (49.79%) | 27 (31.40%) | |||||
| Covariates | ||||||||
| age | 81.12 (6.96) | 76.53 (7.24) | 71.37 (10.39) | 79.57 (5.39) | 48.51 (16.93) | 68.15 (10.59) | 46.54 (15.94) | 59.76 (14.02) |
| gender | 532 (25.93%) | 417 (28.64%) | 474 (56.63%) | 476 (61.34%) | 9166 (52.48%) | 8438 (59.56%) | 3568 (54.53%) | 1177 (58.79%) |
| education | 14.87 (3.15) | 18.25 (3.48) | 15.71 (2.95) | 14.46 (3.39) | 11.60 (2.52) | 12.57 (3.12) | 12.60 (4.19) | 10.32 (1.82) |
| cognition | 6.55 (1.02) | 6.43 (0.98) | 3.92 (1.29) | 4.98 (0.81) | 7.15 (1.63) | 3.08 (2.81) | 5.49 (1.35) | |
| BMI | 27.03 (5.02) | 27.32 (5.39) | 28.28 (5.09) | 25.61 (4.35) | 27.65 (4.42) | 25.42 (7.82) | 25.50 (3.80) | |
| SRhealth | 3.93 (2.94) | 6.75 (2.30) | 6.34 (2.79) | 5.39 (1.89) | 2.16 (2.79) | |||
| smokes | 870 (42.52%) | 285 (19.57%) | 97 (11.58%) | 423 (54.51%) | 5617 (33.97%) | 7935 (56.01%) | 4009 (61.97%) | 998 (49.85%) |
| alcohol | 596 (36.01%) | 362 (27.57%) | 44 (5.25%) | 714 (92.01%) | 9800 (58.31%) | 7523 (53.10%) | 5953 (92.02%) | 1334 (67.89%) |
| race | 361 (17.59%) | 224 (15.38%) | 126 (15.05%) | 343 (44.20%) | 5074 (35.82%) | |||
| stroke | 174 (9.26%) | 96 (6.95%) | 17 (2.03%) | 34 (4.38%) | 0 (0.00%) | 1410 (9.95%) | 52 (0.81%) | 40 (2.06%) |
| cancer | 676 (32.96%) | 444 (30.49%) | 56 (6.68%) | 136 (17.62%) | 0 (0.00%) | 2500 (17.65%) | 104 (1.62%) | 77 (3.98%) |
| diabetes | 275 (13.41%) | 193 (13.26%) | 75 (8.95%) | 141 (18.24%) | 0 (0.00%) | 3376 (23.83%) | 305 (4.76%) | 124 (6.38%) |
| heartProb | 249 (12.15%) | 147 (10.10%) | 70 (8.35%) | 170 (21.91%) | 4367 (30.83%) | 252 (3.93%) | 667 (33.91%) | |
| Note. E = Extraversion; A = Agreeableness; C = Conscientiousness; N = Neuroticism; O = Openness, PA = Positive Affect, NA = Negative Affect, SWL = Satisfaction with Life; Age, education, gender, smoking, alcohol, BMI, chronic conditions, and cognition were assessed at the first baseline personality assessment. | ||||||||
3.2.2 Zero-Order Correlations
r_fun <- function(d){
d <- d[,apply(d, 2, function(x) sum(!is.na(x)) > 0)]
cor(d, use = "pairwise")
}
nested_r <- nested_data %>% select(study, SID, Trait, p_value) %>%
pivot_wider(names_from = "Trait", values_from = "p_value", values_fn = mean) %>%
left_join(
nested_data %>% select(study, SID, Outcome, o_value) %>%
pivot_wider(names_from = "Outcome", values_from = "o_value", values_fn = mean)
) %>%
left_join(
nested_data %>% select(study, SID, age:SRhealth, -dementia) %>%
distinct()
) %>%
select(-SID) %>%
group_by(study) %>%
nest() %>%
ungroup() %>%
mutate(r = map(data, r_fun))3.2.2.1 Table
cor_tab_fun <- function(r, study){
coln <- colnames(r)
colnn <- paste0(1:length(coln), ". ", coln)
r <- apply(r, c(1,2), function(x) sprintf("%.2f", x))
rownames(r) <- colnn; colnames(r) <- 1:length(coln)
r[upper.tri(r)] <- NA
diag(r) <- "--"
tab <- r %>% data.frame() %>%
rownames_to_column("V") %>%
mutate(V = sprintf("<strong>%s</strong>", V)) %>%
kable(.
, "html"
, col.names = c(" ", sprintf("<strong>%i<s/trong>", 1:length(coln)))
, align = c("l", rep("c", length(coln)))
, cap = sprintf("<strong>Table SX</strong><br><em>Zero-Order Correlations Among Variables for %s</em>", study)
, escape = F
) %>%
kable_classic(full_width = F, html_font = "Times")
save_kable(tab, file = sprintf("%s/results/tables/zero-order-cor/%s.html", local_path, study))
return(tab)
}
nested_r <- nested_r %>%
mutate(tab = map2(r, study, cor_tab_fun))
nested_r$tab[[1]]|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
24 |
25 |
26 |
27 |
28 |
29 |
30 |
31 |
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1. A | – | ||||||||||||||||||||||||||||||
| 2. C | 0.29 | – | |||||||||||||||||||||||||||||
| 3. E | 0.25 | 0.23 | – | ||||||||||||||||||||||||||||
| 4. N | -0.33 | -0.31 | -0.34 | – | |||||||||||||||||||||||||||
| 5. O | 0.21 | 0.08 | 0.19 | -0.15 | – | ||||||||||||||||||||||||||
| 6. PA | -0.09 | 0.15 | 0.06 | -0.10 | -0.18 | – | |||||||||||||||||||||||||
| 7. SWL | 0.40 | 0.20 | 0.18 | -0.39 | 0.07 | 0.01 | – | ||||||||||||||||||||||||
| 8. angiopathy | 0.02 | 0.02 | 0.03 | -0.05 | -0.00 | 0.24 | 0.12 | – | |||||||||||||||||||||||
| 9. arteriolosclerosis | 0.03 | -0.01 | -0.01 | 0.03 | -0.14 | -0.34 | -0.18 | 0.04 | – | ||||||||||||||||||||||
| 10. atherosclerosis | -0.08 | -0.04 | 0.00 | 0.01 | -0.11 | -0.14 | 0.04 | 0.06 | 0.30 | – | |||||||||||||||||||||
| 11. braak | 0.04 | -0.01 | 0.06 | -0.03 | 0.01 | -0.07 | 0.07 | 0.34 | 0.04 | 0.02 | – | ||||||||||||||||||||
| 12. cerad | -0.02 | 0.07 | -0.01 | -0.00 | -0.04 | 0.07 | 0.33 | -0.42 | -0.01 | -0.02 | -0.60 | – | |||||||||||||||||||
| 13. hipSclerosis | 0.04 | -0.01 | -0.03 | 0.03 | -0.03 | 0.13 | -0.01 | 0.05 | 0.06 | 0.03 | 0.06 | -0.09 | – | ||||||||||||||||||
| 14. lewyBodyDis | -0.01 | -0.06 | 0.06 | -0.01 | 0.06 | -0.02 | 0.18 | -0.03 | 0.03 | -0.03 | 0.09 | -0.06 | 0.11 | – | |||||||||||||||||
| 15. vsclrInfrcts | -0.01 | 0.01 | -0.07 | -0.00 | -0.07 | -0.11 | -0.22 | 0.03 | 0.21 | 0.26 | 0.02 | -0.03 | -0.05 | -0.01 | – | ||||||||||||||||
| 16. vsclrMcrInfrcts | 0.00 | 0.00 | -0.06 | -0.01 | -0.11 | -0.28 | -0.17 | 0.03 | 0.07 | 0.10 | 0.03 | -0.01 | -0.00 | -0.07 | 0.24 | – | |||||||||||||||
| 17. tdp43 | -0.02 | 0.04 | -0.00 | -0.03 | -0.03 | 0.49 | 0.06 | 0.10 | 0.09 | 0.09 | 0.28 | -0.19 | 0.25 | 0.09 | 0.03 | 0.05 | – | ||||||||||||||
| 18. dementia | -0.08 | -0.10 | -0.04 | 0.06 | -0.12 | 0.04 | 0.08 | 0.15 | 0.15 | 0.15 | 0.36 | -0.33 | 0.18 | 0.19 | 0.14 | 0.09 | 0.23 | – | |||||||||||||
| 19. ageDementia | 0.00 | 0.15 | -0.07 | -0.13 | -0.07 | 0.23 | 0.00 | -0.00 | 0.07 | 0.11 | -0.02 | 0.07 | 0.01 | 0.00 | 0.08 | 0.01 | 0.19 | -0.04 | – | ||||||||||||
| 20. age | -0.04 | -0.05 | -0.07 | 0.00 | -0.16 | 0.30 | 0.18 | 0.13 | 0.19 | 0.23 | 0.17 | -0.13 | 0.05 | 0.01 | 0.16 | 0.01 | 0.19 | 0.18 | 0.57 | – | |||||||||||
| 21. gender | -0.12 | -0.15 | -0.04 | -0.06 | -0.10 | -0.18 | 0.04 | -0.09 | -0.07 | -0.01 | -0.18 | 0.16 | -0.08 | 0.03 | 0.06 | 0.08 | -0.08 | -0.01 | -0.07 | -0.08 | – | ||||||||||
| 22. education | 0.13 | 0.09 | 0.12 | -0.17 | 0.32 | -0.27 | -0.14 | 0.00 | -0.05 | -0.05 | -0.07 | -0.00 | -0.06 | -0.04 | -0.08 | -0.10 | -0.09 | -0.11 | -0.14 | -0.06 | 0.09 | – | |||||||||
| 23. cognition | 0.16 | 0.14 | 0.08 | -0.17 | 0.31 | -0.22 | 0.03 | -0.09 | -0.15 | -0.15 | -0.15 | 0.12 | -0.06 | -0.03 | -0.10 | -0.07 | -0.11 | -0.31 | 0.09 | -0.45 | -0.10 | 0.29 | – | ||||||||
| 24. alcohol | 0.11 | 0.02 | 0.05 | -0.12 | 0.19 | -0.02 | 0.12 | -0.00 | -0.08 | -0.05 | -0.05 | 0.01 | -0.06 | -0.01 | 0.02 | -0.02 | 0.04 | -0.07 | 0.00 | -0.12 | 0.13 | 0.15 | 0.20 | – | |||||||
| 25. smokes | -0.03 | -0.11 | -0.03 | -0.04 | 0.03 | -0.08 | -0.04 | -0.04 | -0.08 | -0.04 | -0.10 | 0.05 | -0.06 | -0.00 | -0.01 | 0.02 | -0.05 | -0.05 | -0.07 | -0.07 | 0.38 | 0.10 | 0.03 | 0.17 | – | ||||||
| 26. BMI | -0.03 | -0.06 | 0.05 | 0.01 | 0.06 | 0.03 | 0.03 | -0.06 | -0.11 | -0.06 | -0.08 | 0.09 | -0.07 | -0.05 | -0.03 | -0.03 | -0.08 | -0.14 | -0.07 | -0.18 | 0.02 | 0.02 | 0.12 | -0.06 | 0.04 | – | |||||
| 27. race | -0.14 | -0.04 | 0.01 | 0.06 | -0.06 | 0.07 | 0.01 | 0.04 | -0.01 | -0.07 | 0.04 | 0.01 | 0.01 | -0.02 | -0.02 | 0.05 | 0.01 | 0.04 | -0.09 | -0.12 | -0.07 | -0.16 | -0.15 | -0.13 | -0.08 | 0.04 | – | ||||
| 28. stroke | -0.05 | -0.09 | -0.09 | 0.06 | -0.05 | 0.01 | -0.14 | -0.05 | 0.10 | 0.09 | -0.04 | -0.02 | -0.08 | -0.08 | 0.15 | 0.10 | -0.00 | 0.02 | -0.06 | 0.10 | 0.03 | -0.00 | -0.11 | -0.04 | 0.00 | -0.04 | 0.01 | – | |||
| 29. cancer | -0.06 | 0.00 | 0.01 | 0.00 | 0.06 | 0.00 | -0.09 | -0.00 | -0.05 | -0.02 | -0.06 | 0.02 | 0.04 | -0.01 | -0.02 | -0.08 | 0.03 | -0.06 | 0.05 | 0.05 | -0.02 | 0.03 | 0.06 | 0.01 | 0.00 | -0.02 | -0.03 | 0.04 | – | ||
| 30. diabetes | -0.02 | -0.07 | 0.04 | 0.01 | 0.01 | 0.09 | -0.11 | -0.02 | 0.02 | -0.06 | -0.01 | -0.06 | 0.02 | 0.02 | 0.02 | 0.01 | -0.08 | -0.04 | -0.11 | -0.02 | 0.06 | -0.00 | -0.07 | -0.08 | 0.02 | 0.23 | 0.12 | 0.02 | 0.03 | – | |
| 31. heartProb | -0.06 | -0.04 | 0.02 | 0.03 | -0.02 | -0.19 | -0.07 | -0.04 | 0.06 | 0.01 | -0.05 | 0.05 | -0.02 | 0.02 | 0.01 | 0.04 | -0.04 | -0.01 | 0.05 | 0.08 | 0.09 | -0.00 | -0.08 | -0.02 | 0.00 | 0.05 | 0.01 | 0.01 | -0.03 | 0.12 | – |
3.2.2.2 Heat Map
r_reshape_fun <- function(r){
coln <- colnames(r)
# remove lower tri and diagonal
r[lower.tri(r, diag = T)] <- NA
r %>% data.frame() %>%
rownames_to_column("V1") %>%
pivot_longer(
cols = -V1
, values_to = "r"
, names_to = "V2"
) %>%
mutate_at(vars(V1, V2), ~factor(., coln))
}
r_plot_fun <- function(r, study){
p <- r %>%
ggplot(aes(x = V1, y = V2, fill = r)) +
geom_raster() +
geom_text(aes(label = round(r, 2))) +
scale_fill_gradient2(limits = c(-1,1)
, breaks = c(-1, -.5, 0, .5, 1)
, low = "blue", high = "red"
, mid = "white", na.value = "white") +
labs(
x = NULL
, y = NULL
, fill = "Zero-Order Correlation"
, title = "Zero-Order Correlations Among Variables"
, subtitle = study
) +
theme_classic() +
theme(
legend.position = "bottom"
, axis.text = element_text(face = "bold")
, axis.text.x = element_text(angle = 45, hjust = 1)
, plot.title = element_text(face = "bold", hjust = .5)
, plot.subtitle = element_text(face = "italic", hjust = .5)
, panel.background = element_rect(color = "black", size = 1)
)
ggsave(p, file = sprintf("%s/results/figures/zero-order-cor/%s.png", local_path, study), width = 14, height = 15)
ggsave(p, file = sprintf("%s/results/figures/zero-order-cor/%s.pdf", local_path, study), width = 14, height = 15)
return(p)
}
nested_r <- nested_r %>%
mutate(r_long = map(r, r_reshape_fun)
, p = map2(r_long, study, r_plot_fun))
nested_r$p[[1]]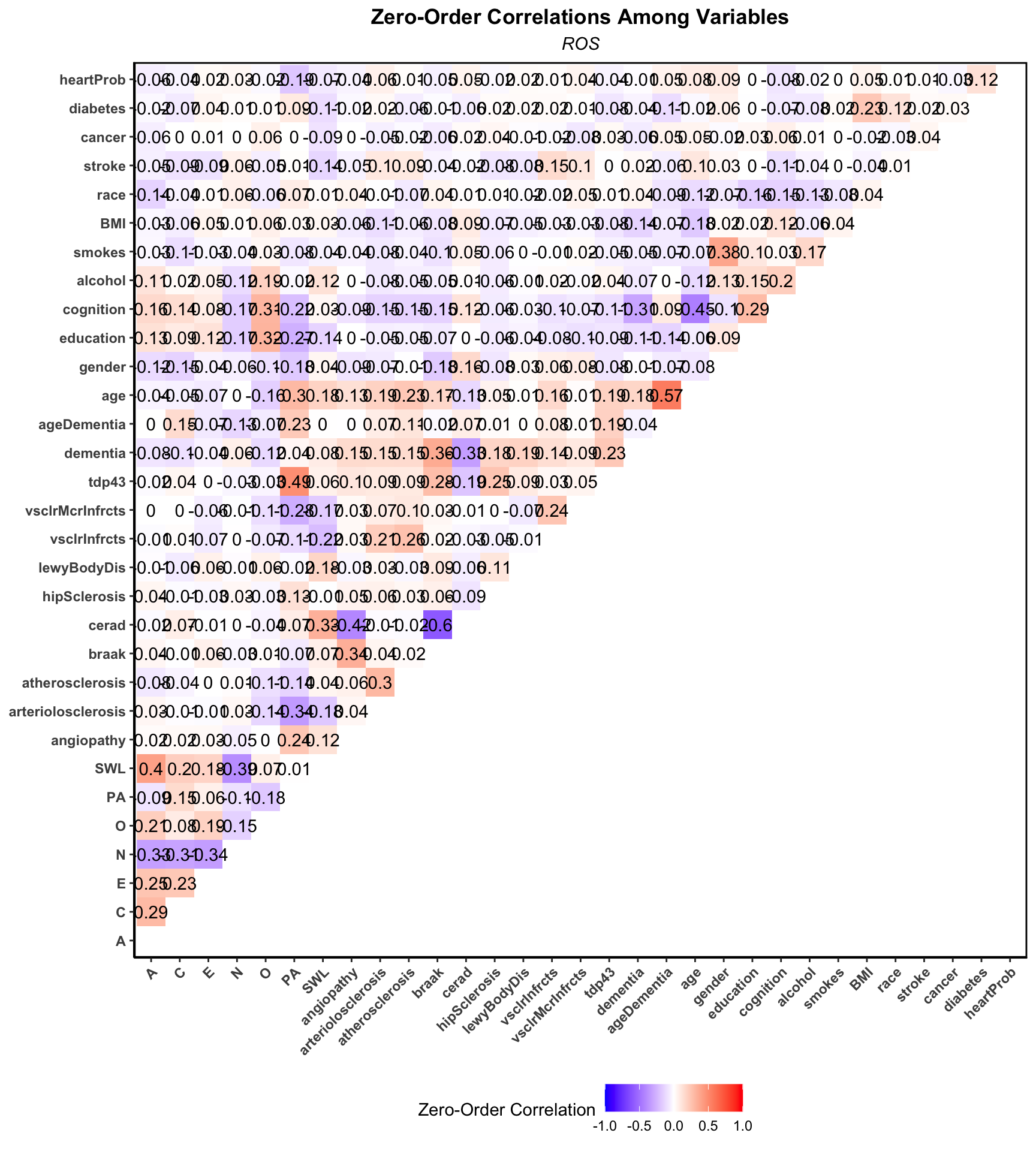
3.2.3 POMP and Factor Levels
The first thing we’ll do is get everything on the same scale. To do so, and as we preregistered, we will convert:
- age to centered at 60
- education (in years) to centered at 12 years
- personality characteristics and cognition to POMP
- chronic conditions to 0 = no, 1 = yes
- Dementia diagnosis to 0 = no, 1 = yes
- Lewy Body Disease (binary; 0 = none, 1 = yes, collapsing across types)
- Gross Cerebral Infarcts, Gross Cerebral Microinfarcts, Hippocampal Sclerosis (binary; 0 = No, 1 = Yes)
All other indicators have scales that are already standardized across studies (e.g., BMI, Braak stage, CERAD) and will not be transformed.
Now let’s:
- POMP personality / well-being and self-rated health
- Create a chronic conditions composite (sum of stroke, cancer, diabetes, heart problem)
- Turn binary indicators into factors
- Center age at 60 years and education at 12 years.
nested_data <- nested_data %>%
group_by(Trait, Outcome, study, p_year) %>%
mutate_at(vars(p_value, SRhealth), ~((. - min(., na.rm = T))/(max(., na.rm = T) - min(., na.rm = T))*10)) %>%
mutate_at(vars(p_value, SRhealth), ~ifelse(is.infinite(.), NA, .)) %>%
ungroup() %>%
mutate(CC = rowSums(cbind(stroke, cancer, diabetes, heartProb), na.rm = T)) %>%
mutate_at(vars(alcohol, smokes, stroke, cancer, diabetes, heartProb, gender, dementia), factor) %>%
mutate(age = age - 60
, education = education - 12
, interval = o_year - p_year)
nested_data## # A tibble: 421,476 × 24
## study SID Trait p_year p_value Outcome o_year o_value age gender education cognition alcohol smokes
## <chr> <chr> <chr> <dbl> <dbl> <chr> <dbl> <dbl> <dbl> <fct> <dbl> <dbl> <fct> <fct>
## 1 ROS 000210… A 0 4.29 angiop… 2 3 20.0 0 10 4.19 0 0
## 2 ROS 000210… A 0 4.29 arteri… 2 0 20.0 0 10 4.19 0 0
## 3 ROS 000210… A 0 4.29 athero… 2 2 20.0 0 10 4.19 0 0
## 4 ROS 000210… A 0 4.29 braak 2 6 20.0 0 10 4.19 0 0
## 5 ROS 000210… A 0 4.29 cerad 2 1 20.0 0 10 4.19 0 0
## 6 ROS 000210… A 0 4.29 hipScl… 2 0 20.0 0 10 4.19 0 0
## 7 ROS 000210… A 0 4.29 lewyBo… 2 0 20.0 0 10 4.19 0 0
## 8 ROS 000210… A 0 4.29 vsclrI… 2 0 20.0 0 10 4.19 0 0
## 9 ROS 000210… A 0 4.29 vsclrM… 2 1 20.0 0 10 4.19 0 0
## 10 ROS 000210… A 0 4.29 tdp43 2 1 20.0 0 10 4.19 0 0
## # ℹ 421,466 more rows
## # ℹ 10 more variables: BMI <dbl>, race <dbl>, stroke <fct>, cancer <fct>, diabetes <fct>, heartProb <fct>,
## # dementia <fct>, SRhealth <dbl>, CC <dbl>, interval <dbl>3.2.4 Rescale Outcomes
Now that we’ve got personality and covariates scaled, we will group by personality characteristic and outcome to rescale outcomes, as needed.
save_fun <- function(d, trait, outcome){
if(outcome %in% c("dementia", "hipSclerosis", "lewyBodyDis", "tdp43", "vsclrInfrcts", "vsclrMcrInfrcts")){
d <- d %>% mutate(o_value = factor(o_value))
}
save(d, file = sprintf("%s/data/SCA/%s-%s.RData", local_path, trait, outcome))
return(d)
}
nested_data <- nested_data %>%
group_by(Trait, Outcome) %>%
nest() %>%
ungroup() %>%
mutate(data = pmap(list(data, Trait, Outcome), save_fun))
nested_data ## # A tibble: 96 × 3
## Trait Outcome data
## <chr> <chr> <list>
## 1 A angiopathy <tibble [909 × 22]>
## 2 A arteriolosclerosis <tibble [926 × 22]>
## 3 A atherosclerosis <tibble [943 × 22]>
## 4 A braak <tibble [969 × 22]>
## 5 A cerad <tibble [889 × 22]>
## 6 A hipSclerosis <tibble [844 × 22]>
## 7 A lewyBodyDis <tibble [935 × 22]>
## 8 A vsclrInfrcts <tibble [934 × 22]>
## 9 A vsclrMcrInfrcts <tibble [934 × 22]>
## 10 A tdp43 <tibble [791 × 22]>
## # ℹ 86 more rows3.2.5 Bring in Moderators and Covariate Adjustments
These full data sets will be used for sensitivity analyses and adjusted models, but we also want to set up our data for unadjusted models and moderator tests. For robusteness, we are using a few different sets of theoretically plausible covariates. The goal is to ensure that the pattern of results is not greatly impacted by the inclusion of different covariates. Not knowing the answer to this can be a threat to good science.
mod_setup_fun <- function(d, trait, outcome){
crossing(Covariates = c("fully", "shared", "standard", "butOne", "unadjusted", "shareddx", "standarddx", "sharedint", "int")
, Moderator = c("none", "education", "age", "gender", "cognition", "dementia")) %>%
mutate(data = list(d)) %>%
# filter(Covariates == "sharedint") %>%
mutate(data = pmap(list(data, trait, outcome, Moderator, Covariates), mod_save_fun))
return(NULL)
}
mod_save_fun <- function(d, trait, outcome, mod, cov){
covs <- if(cov == "unadjusted"){
mod
} else if (cov %in% c("shared", "shareddx", "sharedint")){
c(mod, "age", "gender", "education", "smokes", "alcohol")
} else if (cov %in% c("standard", "standarddx")){
c(mod, "age", "gender", "education")
} else if(cov == "butOne"){
c(mod, "age", "gender", "education", "smokes", "alcohol", "cognition", "CC")
} else{
colnames(d)
}
if(grepl("dx", cov)) covs <- c(covs, "dementia")
if(grepl("int", cov)) covs <- c(covs, "interval")
d2 <- d %>% select(study, SID, p_year, p_value, o_year, o_value, one_of(covs), one_of(mod)) %>% filter(complete.cases(.))
# d2 <- if(cov == "unadjusted"){
# d %>% select(study, SID, p_year, p_value, o_year, o_value, one_of(mod)) %>% filter(complete.cases(.))
# } else if (cov == "shared"){
# d %>% select(study, SID, p_year, p_value, o_year, o_value, one_of(mod), age, gender, education, smokes, alcohol) %>% filter(complete.cases(.))
# } else if (cov == "standard"){
# d %>% select(study, SID, p_year, p_value, o_year, o_value, one_of(mod), age, gender, education) %>% filter(complete.cases(.))
# } else if (cov == "butOne") {
# d %>% select(study, SID, p_year, p_value, o_year, o_value, one_of(mod), age, gender, education, smokes, alcohol, cognition, CC) %>% filter(complete.cases(.))
# } else {
# d %>% filter(complete.cases(.))
# }
# if(mod != "none") colnames(d2)[colnames(d2) == mod] <- "modvalue"
save(d2, file = sprintf("%s/data/mega-analysis/%s/%s-%s-%s.RData"
, local_path, cov, trait, outcome, mod))
return(NULL)
}
nested_data %>%
# filter(Outcome != "dementia") %>%
mutate(data = pmap(list(data, Trait, Outcome), mod_setup_fun))Here’s one example:
load("/Volumes/Emorie/projects/dementia/prediction/data/mega-analysis/shared/A-angiopathy-gender.RData")
d2## # A tibble: 817 × 11
## study SID p_year p_value o_year o_value gender age education smokes alcohol
## <chr> <chr> <dbl> <dbl> <dbl> <dbl> <fct> <dbl> <dbl> <fct> <fct>
## 1 ROS 00021073 0 4.29 2 3 0 20.0 10 0 0
## 2 ROS 10100312 0 6.07 13 2 1 15.3 8 0 1
## 3 ROS 10100448 0 5 15 0 1 12.4 11 1 1
## 4 ROS 10100574 0 5.71 9 1 1 13.7 9 0 1
## 5 ROS 10100736 0 6.07 9 0 1 20.8 2 1 1
## 6 ROS 10101039 0 5.71 8 1 1 23.4 7 1 1
## 7 ROS 10101291 0 4.29 1 0 1 21.5 3 1 0
## 8 ROS 10101327 0 3.57 2 1 1 26.9 9 1 0
## 9 ROS 10101589 0 6.07 6 1 1 42.1 8 0 0
## 10 ROS 10101741 0 5 12 1 1 23.3 -2 0 0
## # ℹ 807 more rows3.3 Part 3: Models
For these first models, we’ll be testing three sets of covariates. For a full test of how covariates impact our inferences, we’ll then follow up in a later step doing a specification curve / multiverse analysis.
For these first models, we will run a series of Bayesian regressions. For binary outcomes, these will be multilevel logistic regressions, while for the others, these will be “regular” multilevel linear regressions. For each of these, we will also test age, gender, and education, and cognitive functioning as moderators.
3.3.1 Functions
3.3.1.1 Model Function
ipd_mega_mod_fun <- function(trait, outcome, mod, cov){
print(paste(trait, outcome, mod, cov))
## load the data
load(sprintf("%s/data/mega-analysis/%s/%s-%s-%s.RData", local_path, cov, trait, outcome, mod))
## compiled Bayesian model to speed up processing and avoid crashing
if(outcome %in% c("dementia", "hipSclerosis", "lewyBodyDis", "tdp43", "vsclrInfrcts", "vsclrMcrInfrcts")) load(sprintf("%s/results/bayes_sample_mod_binomial.RData", local_path)) else load(sprintf("%s/results/bayes_sample_mod_continuous.RData", local_path))
## formula
cv <- c("age", "gender", "education", "smokes", "alcohol")
#if (cov == "shared") cv <- cv
if (cov == "butOne") cv <- c(cv, "CC", "cognition")
if (cov == "fully") cv <- c(cv, "CC", "cognition", "BMI", "race", "SRhealth")
if (grepl("standard", cov)) cv <- c("age", "gender", "education")
if(grepl("dx", cov)) cv <- c(cv, "dementia")
if(grepl("int", cov)) cv <- c(cv, "interval")
rhs <- "p_value"
rhs <- if(cov != "unadjusted") c(rhs, cv) else rhs
if(mod != "none") rhs <- c(rhs, paste("p_value", mod, sep = "*"))
re <- if(mod == "none") "(p_value | study)" else paste(paste("(p_value", mod, sep = " * "), "| study)")
rhs <- paste(c(rhs, re), collapse = " + ")
f <- paste("o_value ~ ", rhs, collapse = "")
## run the models & save
m <- update(m
, formula = f
, newdata = d2
, iter = 1000
, warmup = 500
, cores = 12
, threads = threading(3)
, backend = "cmdstanr"
, chains = 4
)
save(m, file = sprintf("%s/results/models/%s/%s_%s_%s.RData"
, local_path, cov, outcome, trait, mod))
## extract model terms and confidence intervals & save
fx <- tidy(m, conf.int = T) %>%
select(term, estimate, conf.low, conf.high)
rx <- std_eff_fun(m)
save(fx, rx, file = sprintf("%s/results/summary/%s/%s_%s_%s.RData"
, local_path, cov, outcome, trait, mod))
## extract heterogeneity estimates
het <- hetero_fun(m)
save(het, file = sprintf("%s/results/heterogeneity/%s/%s_%s_%s.RData"
, local_path, cov, outcome, trait, mod))
if(mod != "none"){
# load(sprintf("%s/results/models/%s/%s_%s_%s.RData", local_path, cov, outcome, trait, mod))
pred.fx <- fx_pred_fun(m, mod)
pred.rx <- rx_pred_fun(m, mod)
save(pred.fx, pred.rx, file = sprintf("%s/results/predicted/%s/%s_%s_%s.RData"
, local_path, cov, outcome, trait, mod))
# rm(list = c("pred.fx", "pred.rx", "m"))
# gc()
# return(T)
}
## clean up the local function environment
rm(list = c("d", "f", "rhs", "m", "fx", "rx", "het"))
gc()
}3.3.1.2 Study-Specific Effects Function
As noted previously, once we run the model, we will have to use a second step to get the study-specific estimates for all studies. Unlike with dummy codes, doing so is much more straightforward. We just have to pull study-specific effects using the coef() for both Bayesian and Frequentist approaches.
std_eff_fun <- function(m){
coef(m, probs = c(0.025, 0.975))[[1]] %>% array_tree(3) %>%
tibble(names = names(.), data = .) %>%
mutate(data = map(data, ~(.) %>% data.frame %>%
rownames_to_column("study"))) %>%
unnest(data) %>%
select(names, study, estimate = Estimate, conf.low = Q2.5, conf.high = Q97.5)
}3.3.1.3 Heterogeneity Estimates Function
The Final pieces of information we need to extract from these models are estimates of the heterogeneity of effects across studies.
hetero_fun <- function(m){
args <- list(x = m, effects = "ran_pars", conf.int = T)
do.call(tidy, args) %>%
select(group, term, estimate, conf.low, conf.high) %>%
separate(term, c("est", "term"), sep = "__") %>%
mutate_at(vars(estimate:conf.high), ~ifelse(est == "sd", .^2, .)) %>%
mutate(est = ifelse(est == "sd", "var", est))
}3.3.1.4 Simple Effects Function
3.3.1.4.1 Fixed Effects
fx_pred_fun <-function(m, moder){
d <- m$data
d <- d %>% select(-o_value, -study)
cols <- colnames(d)
mdr <- if(moder == "dementia") "p_value" else moder
md_cl <- class(d[,mdr])
if(any(sapply(d, class) == "numeric")){
msd <- d %>%
select_if(is.numeric) %>%
pivot_longer(everything()
, names_to = "item"
, values_to = "value") %>%
group_by(item) %>%
summarize_at(vars(value), lst(mean, sd)) %>%
ungroup()
}
if(any(sapply(d, class) == "factor")){
fct_lev <- d %>%
select_if(is.factor) %>%
summarize_all(~list(levels(.)))
}
d <- d %>% select(-one_of(moder), -p_value)
md_levs <- if(md_cl == "numeric"){
if(mdr %in% c("age")) {
c(-10, 0, 10)
} else if (mdr %in% c("education")) {
c(-5, 0, 5)
} else {
with(msd, c(mean[item == mdr] - sd[item == mdr], mean[item == mdr], mean[item == mdr] + sd[item == mdr]))
}
} else {
sort(unique(fct_lev[,moder][[1]]))
}
md_fac <- if(moder == "age") c("-10 yrs", "60", "+10 yrs") else if (moder == "education") c("-5 yrs", "12 years", "+5 yrs") else if(moder == "gender") c("Male", "Female") else c("-1 SD", "M", "+1 SD")
if(moder != "dementia"){
mod_frame <- expand.grid(
p_value = seq(0,10,.1)
, modvalue = md_levs
, stringsAsFactors = F
) %>%
mutate(mod_fac = factor(modvalue, levels = unique(modvalue), labels = md_fac)) %>%
setNames(c("p_value", moder, "mod_fac"))
} else {
mod_frame <- expand.grid(
p_value = with(msd, c(mean[item == "p_value"] - 2.5, mean[item == "p_value"], mean[item == "p_value"] + 2.5))
, dementia = c(0,1)
) %>%
mutate(mod_fac = factor(p_value, levels = unique(p_value), labels = c("-25%", "M", "+25%")))
}
if(ncol(d) > 0){
if(any(sapply(d, class) == "numeric")){
mod_frame <- tibble(mod_frame, d %>% select_if(is.numeric) %>% summarize_all(mean))
}
if(any(sapply(d, class) == "factor")){
fcts <- colnames(d)[sapply(d, class) == "factor"]
for(i in 1:length(fcts)){
fct <- fcts[i]
mod_frame <- crossing(
mod_frame
, levels(d[,fct])
) %>% setNames(c(colnames(mod_frame), fct))
}
}
}
if(moder != "dementia") {
pred.fx <- bind_cols(
mod_frame,
fitted(m
, newdata = mod_frame
, re_formula = NA) %>% data.frame
) %>%
select(one_of(colnames(m$data)), mod_fac, pred = Estimate, lower = Q2.5, upper = Q97.5) %>%
group_by(p_value, mod_fac) %>%
summarize_at(vars(pred, lower, upper), mean) %>%
ungroup()
} else {
pred.fx <- epred_draws(m, mod_frame, re_formula = NA)
pred.fx <- pred.fx %>%
ungroup() %>%
filter(dementia == 1) %>%
select(p_value, mod_fac, .epred_1 = .epred) %>%
bind_cols(pred.fx %>%
ungroup() %>%
filter(dementia == 0) %>%
select(.epred_0 = .epred)
) %>%
mutate(diff = .epred_1 - .epred_0) %>%
select(-.epred_1, -.epred_0) %>%
group_by(p_value, mod_fac) %>%
median_qi() %>%
select(p_value, mod_fac, pred = diff, lower = .lower, upper = .upper)
}
rm(list = c("m", "mod_frame", "d", "md_levs"))
gc()
return(pred.fx)
}3.3.1.4.2 Study-Specific Effects
rx_pred_fun <- function(m, moder){
d <- m$data
d <- d %>% select(-o_value)
cols <- colnames(d)
mdr <- if(moder == "dementia") "p_value" else moder
md_cl <- class(d[,mdr])
if(any(sapply(d, class) == "numeric")){
msd <- d %>%
group_by(study) %>%
select_if(is.numeric) %>%
pivot_longer(-study
, names_to = "item"
, values_to = "value") %>%
group_by(study, item) %>%
summarize_at(vars(value), lst(mean, sd), na.rm = T) %>%
ungroup()
}
if(any(sapply(d, class) == "factor")){
fct_lev <- d %>%
group_by(study) %>%
select_if(is.factor) %>%
summarize_all(~list((levels(.)))) %>%
ungroup()
}
d <- d %>% select(-one_of(moder), -p_value)
md_fac <- if(moder == "age") c("-10 yrs", "60", "+10 yrs") else if (moder == "education") c("-5 yrs", "12 years", "+5 yrs") else if(moder == "gender") c("Male", "Female") else c("-1 SD", "M", "+1 SD")
md_levs <- if(!moder %in% c("cognition", "dementia")){
crossing(
study = unique(d$study)
, modvalue = if(mdr == "age") c(-10, 0, 10) else if (mdr == "education") c(-5,0,5) else c(0,1)
) %>%
mutate(mod_fac = factor(modvalue, levels = unique(modvalue), labels = md_fac)) %>%
setNames(c("study", moder, "mod_fac"))
} else if(moder != "dementia") {
msd %>%
filter(item == moder) %>%
mutate(lower = mean - sd, upper = mean + sd) %>%
select(-sd) %>%
pivot_longer(cols = c(mean, lower, upper)
, names_to = "meas"
, values_to = "modvalue") %>%
pivot_wider(names_from = "item", values_from = "modvalue") %>%
select(study, one_of(moder)) %>%
setNames(c("study", "modvalue")) %>%
group_by(study) %>%
mutate(mod_fac = factor(modvalue, levels = sort(unique(modvalue)), labels = md_fac)) %>%
ungroup() %>%
setNames(c("study", moder, "mod_fac"))
} else {
msd %>%
filter(item == mdr) %>%
mutate(lower = mean - 2.5, upper = mean + 2.5) %>%
select(-sd) %>%
pivot_longer(cols = c(mean, lower, upper)
, names_to = "meas"
, values_to = "modvalue") %>%
pivot_wider(names_from = "item", values_from = "modvalue") %>%
select(study, meas, one_of(mdr)) %>%
setNames(c("study", "meas", "modvalue")) %>%
group_by(study) %>%
mutate(mod_fac = factor(meas, levels = c("lower", "mean", "upper"), labels = c("-25%", "M", "+25%"))) %>%
ungroup() %>%
select(-meas) %>%
setNames(c("study", mdr, "mod_fac"))
}
mod_frame <- if(moder != "dementia"){
crossing(
p_value = seq(0,10,.1)
, md_levs
)
} else {
crossing(
md_levs
, dementia = c(0,1)
)
}
if(ncol(d) > 0){
if(any(sapply(d, class) == "numeric")){
mod_frame <- d %>%
group_by(study) %>%
select_if(is.numeric) %>%
summarize_all(mean, na.rm = T) %>%
ungroup() %>%
full_join(mod_frame)
}
if(any(sapply(d, class) == "factor")){
fcts <- colnames(d)[sapply(d, class) == "factor"]
for(i in 1:length(fcts)){
fct <- fcts[i]
mod_frame <- crossing(
mod_frame
, levels(d[,fct])
) %>% setNames(c(colnames(mod_frame), fct))
}
}
}
if(moder != "dementia") {
pred.rx <- bind_cols(
mod_frame,
fitted(m
, newdata = mod_frame) %>% data.frame
) %>%
select(one_of(colnames(m$data)), mod_fac, pred = Estimate, lower = Q2.5, upper = Q97.5) %>%
group_by(p_value, mod_fac, study) %>%
summarize_at(vars(pred, lower, upper), mean) %>%
ungroup()
} else {
pred.rx <- epred_draws(m, mod_frame)
pred.rx <- pred.rx %>%
ungroup() %>%
filter(dementia == 1) %>%
select(study, p_value, mod_fac, .epred_1 = .epred) %>%
bind_cols(pred.rx %>%
ungroup() %>%
filter(dementia == 0) %>%
select(.epred_0 = .epred)
) %>%
mutate(diff = .epred_1 - .epred_0) %>%
select(-.epred_1, -.epred_0) %>%
group_by(study, p_value, mod_fac) %>%
median_qi() %>%
select(study, p_value, mod_fac, pred = diff, lower = .lower, upper = .upper)
}
rm(list = c("m", "mod_frame", "d"))
gc()
return(pred.rx)
}3.3.2 Run Models and Summaries
3.3.2.1 Sample Bayesian Models
Before we actually run the models, we will estimate two models on smaller subsets of data. The advantage to this is that it prevents the rstan model from having to recompile the model, which speeds up runtime and prevents random crashes. It’s going to fit badly. That’s fine. It was given almost no data.
# Sample Bayesian Model
# load data
load(sprintf("%s/data/mega-analysis/sharedint/N-dementia-none.RData", local_path))
# load("data/mega-analysis/shared/N-dementia-none.RData")
# clean data & keep only needed columns and a subset of the used variables
d <- d2 %>%
group_by(study) %>%
nest() %>%
ungroup() %>%
mutate(data = map(data, ~(.) %>% filter(row_number() %in% sample(1:nrow(.), 100, replace = F)))) %>%
unnest(data)
# set priors & model specifications
Prior <- c(set_prior("cauchy(0,1)", class = "sd"),
set_prior("student_t(3, 0, 2)", class = "b"),
set_prior("student_t(3, 0, 5)", class = "Intercept"))
Iter <- 30; Warmup <- 21; treedepth <- 20
f <- formula(o_value ~ p_value + age + gender + interval + p_value*education + (p_value*education | study))
m <- brm(formula = f
, data = d
, family = bernoulli(link = "logit")
, prior = Prior
, iter = Iter
, warmup = Warmup
, cores = 12
, threads = threading(3)
, backend = "cmdstanr"
, chains = 4)
save(m, file = sprintf("%s/results/bayes_sample_mod_binomial.RData", local_path))
# save(m, file = "results/bayes_sample_mod_binomial.RData")
load(sprintf("%s/data/mega-analysis/sharedint/N-braak-none.RData", local_path))
# load("data/mega-analysis/shared/N-braak-none.RData")
# clean data & keep only needed columns and a subset of the used variables
d <- d2 %>%
group_by(study) %>%
nest() %>%
ungroup() %>%
mutate(data = map(data, ~(.) %>% filter(row_number() %in% sample(1:nrow(.), 100, replace = T)))) %>%
unnest(data)
# set priors & model specifications
Prior <- c(set_prior("cauchy(0,1)", class = "sd"),
set_prior("student_t(3, 0, 2)", class = "b"),
set_prior("student_t(3, 0, 5)", class = "Intercept"))
Iter <- 30; Warmup <- 21; treedepth <- 20
f <- formula(o_value ~ p_value + age + gender + interval + p_value*education + (p_value*education | study))
m <- brm(formula = f
, data = d
, prior = Prior
, iter = Iter
, warmup = Warmup
, cores = 12
, threads = threading(3)
, backend = "cmdstanr"
, chains = 4)
save(m, file = sprintf("%s/results/bayes_sample_mod_continuous.RData", local_path))
# save(m, file = "results/bayes_sample_mod_continuous.RData")
rm(list = c("d", "Prior", "Iter", "Warmup", "treedepth", "f", "m"))3.3.2.1.1 Binary
## Family: bernoulli
## Links: mu = logit
## Formula: o_value ~ p_value + age + gender + interval + p_value * education + (p_value * education | study)
## Data: d (Number of observations: 800)
## Draws: 4 chains, each with iter = 30; warmup = 21; thin = 1;
## total post-warmup draws = 36
##
## Group-Level Effects:
## ~study (Number of levels: 8)
## Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
## sd(Intercept) 0.63 0.46 0.05 1.46 1.41 16 16
## sd(p_value) 0.31 0.16 0.05 0.70 0.99 16 16
## sd(education) 0.10 0.07 0.02 0.28 1.02 16 16
## sd(p_value:education) 0.04 0.03 0.00 0.11 1.10 16 16
## cor(Intercept,p_value) 0.09 0.40 -0.60 0.79 0.97 16 16
## cor(Intercept,education) 0.03 0.34 -0.59 0.60 1.25 16 16
## cor(p_value,education) -0.21 0.43 -0.83 0.72 0.98 16 16
## cor(Intercept,p_value:education) 0.13 0.43 -0.67 0.86 1.10 16 16
## cor(p_value,p_value:education) 0.20 0.41 -0.66 0.76 1.23 16 16
## cor(education,p_value:education) -0.15 0.40 -0.71 0.65 1.29 16 16
##
## Population-Level Effects:
## Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
## Intercept -5.20 0.81 -6.76 -3.93 1.08 16 16
## p_value -0.00 0.16 -0.24 0.30 1.07 16 16
## age 0.13 0.02 0.09 0.16 0.95 16 16
## gender1 -0.28 0.33 -0.76 0.31 1.08 16 16
## interval 0.16 0.03 0.12 0.22 1.07 16 16
## education -0.04 0.13 -0.21 0.27 1.22 16 16
## p_value:education -0.01 0.03 -0.06 0.06 1.20 16 16
##
## Draws were sampled using sample(hmc). For each parameter, Bulk_ESS
## and Tail_ESS are effective sample size measures, and Rhat is the potential
## scale reduction factor on split chains (at convergence, Rhat = 1).3.3.2.2 Run the Models
done <- tibble(Covariate = c("fully", "shared", "butOne", "unadjusted", "standard", "standarddx", "shareddx", "sharedint"),
file = map(Covariate, ~list.files(sprintf("%s/results/models/%s", local_path, .)))) %>%
unnest(file) %>%
separate(file, c("Outcome", "Trait", "Moderator"), sep = "_") %>%
mutate(Moderator = str_remove_all(Moderator, ".RData")
, done = "done") %>%
filter(!is.na(Moderator))
# plan(multisession(workers = 4L))
nested_ipd_mega <- crossing(
Trait = traits$short_name
, Outcome = outcomes$short_name
, Moderator = c("education", "age", "gender", "cognition", "dementia")
, Covariate = c("fully", "shared", "butOne", "standard", "unadjusted", "standarddx", "shareddx", "sharedint")
) %>%
full_join(
crossing(
Trait = traits$short_name
, Outcome = outcomes$short_name
, Moderator = "none"
, Covariate = c("fully", "shared", "butOne", "standard", "unadjusted", "standarddx", "shareddx", "sharedint") # "int",
)
) %>%
# mutate(run = future_pmap(
mutate(run = pmap(
list(Trait, Outcome, Moderator, Covariate)
, possibly(ipd_mega_mod_fun, NA_real_)
# , ipd_mega_mod_fun
# , .options = furrr_options(
# globals = c("traits", "moders", "covars", "outcomes"
# , "hetero_fun"
# , "rx_pred_fun"
# , "std_eff_fun"
# , "fx_pred_fun"
# , "local_path")
# , packages = c("broom", "broom.mixed", "tidyverse", "brms")
# )
# , .progress = T
))
# nested_ipd_mega %>%
# mutate(Covariate = factor(Covariate)
# , Covariate = relevel(Covariate, "shared")
# # , Moderator = factor(Moderator, levels = moders$short_name)
# , Moderator = relevel(factor(Moderator), "dementia")
# ) %>%
# arrange(Covariate, Outcome, Moderator, Trait) %>%
# filter(Covariate != "fully") %>%
# select(Trait, Outcome, Moderator, Covariate) %>%
# write.table(.
# , file = sprintf("%s/scripts/cluster/args/args.txt", local_path)
# , row.names = F)