library(furrr) # note loading this last ONLY because it depends on tidyverse and will not mask it
Outline
Questions on Homework
Git/GitHub
Parallelization using future
furrr
What and why use Git and GitHub?
Video from Will Doyle, Professor at Vanderbilt University
What is version control?
Version control is a “system that records changes to a file or set of files over time so that you can recall specific versions later”
Keeps records of changes, who made changes, and when those changes were made
You or collaborators take “snapshots” of a document at a particular point in time. Later on, you can recover any previous snapshot of the document.
How version control works:
Imagine you write a simple text file document that gives a recipe for yummy chocolate chip cookies and you save it as cookies.txt
Later on, you make changes to cookies.txt (e.g., add alternative baking time for people who like “soft and chewy” cookies)
When using version control to make these changes, you don’t save entirely new version of cookies.txt; rather, you save the changes made relative to the previous version of cookies.txt
Why use Git and GitHub?
Why use version control when you can just save new version of document?
Saving entirely new document each time a change is made is very inefficient from a memory/storage perspective
When you save a new version of a document, much of the contents are the same as the previous version
Inefficient to devote space to saving multiple copies of the same content
When document undergoes lots of changes – especially a document that multiple people are collaborating on – it’s hard to keep track of so many different documents. Easy to end up with a situation like this:
“Git is a free and open source distributed version control system designed to handle everything from small to very large projects with speed and efficiency”
Git is a particular version control software created by The Git Project
A repository “encompasses the entire collection of files and folders associated with a project, along with each file’s revision history”
Because git is a distributed version control system, “repositories are self-contained units and anyone who owns a copy of the repository can access the entire codebase and its history”
Local git repository: git repository for a project stored on your machine
Remote git repository: git repository for a project stored on the internet
Typically, a local git repository is connected to a remote git repository
You can make changes to local repository on your machine and then push those changes to the remote repository
Other collaborators can also make changes to their local repository, push them to the remote repository, and then you can pull these changes into your local repository
Private vs. public repositories
Public repositories: anyone can access the repository
e.g., PSC290 FQ23, the git repository we created to develop this course is a public repository because we want the public to benefit from this course
Private repositories: only those who have been granted access by a repository “administrator” can access the repository
What is GitHub?
GitHub is the industry standard hosting site/service for Git repositories
Hosting services allow people/organizations to store files on the internet and make those files available to others
Microsoft acquired Github in 2018 for $7.5 billion
Github is where remote git repositories live
Git Workflow
Version control systems that save differences: - Prior to Git, “centralized version control systems” were the industry standard version control systems (From Getting Started - About Version Control) - In these systems, a central server stored all the versions of a file and “clients” (e.g., a programmer working on a project on their local computer) could “check out” files from the central server - These centralized version control systems stored multiple versions of a file as “differences” - The below figure portrays version control systems that store data as changes relative to the base version of each file:
Git stores data as snapshots rather than differences:
Git doesn’t think of data as differences relative to the base version of each file
Rather, Git thinks of data as “a series of snapshots of a miniature filesystem” or, said differently, a series of snapshots of all files in the repository
For files that have changed:
the “commit” will save lines that you have changed or added [like “differences”]
lines that have not changed will not be re-saved; because these lines have been saved in previous commit(s) that are linked to the current commit
Git Workflow
The below figure portrays storing data as a stream of snapshots over time:
Local working directory (also called “working tree”)
This is the area where all your work happens! You are writing Rmd files, debugging R scripts, adding and deleting files
These changes are made on your local machine!
Git index/staging area (git add <filename(s)> command)
The staging area is the area between your local working directory and the repository, where you list changes you have made in the local working directory that you would like to commit to the repository
Repository (git commit command)
This is the actual repository where Git permanently stores the changes you’ve made in the local working directory and added to the staging area
Git Workflow
Hypothetical work flow to cookies.txt:
Add changes from local working directory to staging area
Commit changes from staging area to repository
Each commit to the repository is a different version of the file that represents a snapshot of the file at a particular time
Commits are made to branches in the repo
By default, a git repository comes with one main branch (typically called main)
But we can also create other branches (discussed more later)
Git Workflow
Local vs. remote repository
When you add a change to the staging area and then commit the change to your repository, this changes your local repository (i.e., on your computer) rather than your remote repository (i.e., on GitHub)
If you want to change the remote repository (typically named origin), you must push the change from your local repository to your remote repository
As seen below, each circle represents a commit. After you make commits on a branch in your local repository (i.e., main), you need to push them in order for the corresponding branch on the remote repository (i.e., origin/main) to be up-to-date with your changes.
GitHub Desktop
Practically, in this class, I’m going to show you how to use GitHub Desktop, which is a GUI (graphical user interface) for managing git repositories and commits.
Relative to the command line, using a GUI means you’re ready to be “up and running with git immediately and don’t have to learn bash syntax
ggplot(penguins, aes(x = bill_length_mm, y = bill_depth_mm, color = species)) +geom_point() +labs(title ="Penguin bills") +theme_classic()
Staging your files
Stage your file
Commit your changes
Commit your changes
Use an informative commit message
(Not great) “Analyze data” 😞
(Better) “Estimate logistic regression” 🎉
Have a consistent style
Start with an action verb
Capitalize message
Commits are cheap, use them often!
Push your changes
Why Use Git/Hub
Direct link to the Open Science Framework via “Add-ons,” so you don’t have to maintain / copy files multiple places
Easy collaboration with better tools for dealing with conflicts due to remotes
Easy to restore back to an earlier “snapshot”
Can directly link to files, data, etc.
by default, the links will be to the “main”
swap this out for “raw” and it will link to the raw file, which will open a raw text page for text files (including .csv) or download (including .docx, .pdf, etc.)
Parallel Processing in R
Guarding your resources
Computers have finite resources
A common source of issues in R is a cluttered environment
Objects you aren’t using
Objects unrelated to whatever you’re working on, etc.
Cleaning up your environment
The best ways to avoid issues due to a cluttered environment are:
Always start from a blank environment
Write scripts systematically. You shouldn’t be skipping around and should be careful about overwriting objects
Save object(s), not your whole workspace to allow you to bring back in things you were working on previously
Use object names with clear patterns to allow you clean up your environment
rm(list=ls()[grepl("RQ1", ls()])
rm(list=ls()[!ls() %in% c("df1", "df2")])
Occasionally call gc() after cleaning up your environment
Guarding your resources
All of the above guard your RAM, but another cause of issues with resources is that you take full advantage of your computing power
Most modern computers have 8+ physical and virtual cores and powerful graphics cards
Together, these allow us to parallelize processes, which just means to do multiple different processes in parallel at the same time
Parallel Processing
You’ve likely used parallel processing in R before
Many packages, like lavaan, lme4, and any bootstrapping have an argument called parallel, with values like TRUE/FALSE or “fork”/“multisession”/“multicore”
This just means that they are using one of many available packages / tools to speed up the estmation of whatever your function is doing
Why use future for parallelization?
A Unifying Parallelization Framework in R for Everyone
Require only minimal changes to parallelize existing R code
“Write once, Parallelize anywhere
Same code regardless of operating system and parallel backend
Lower the bar to get started with parallelization
Fewer decisions for the developer to make
Stay with your favorite coding style
Worry-free: globals, packages, output, warnings, errors just work
Statistically sound: Built-in parallel random number generation (RNG)
Correctness and reproducibility of highest priority
Three atomic building blocks
There are three atomic building blocks that do everything we need:
f <- future(expr) : evaluates an expression via a future (non-blocking, if possible)
rs <- resolved(f) : TRUE if future is resolved, otherwise FALSE (non-blocking)
v <- value(f) : the value of the future expression expr (blocking until resolved)
Example
To break down what’s happening, let’s use a bad function, called slow_sum()
Code
slow_sum <-function(x) { sum <-0for (kk inseq_along(x)) { sum <- sum + x[kk]Sys.sleep(0.1) # emulate 0.1 second cost per addition } sum}
But with future, we can parallelize and continue to run other things:
Code
f1 <-future(slow_sum(x_head)) ## ~5 secs (in parallel)f2 <-future(slow_sum(x_tail)) ## ~5 secs (in parallel)## Do other thingsz <-sd(x)v <-value(f1) +value(f2) ## ready after ~5 secs
Setting up your future backend
To fully make use of future, you need to understand:
parallel backends
“workers”
globals
packages
Parallel backends
There are multiple ways that you can run parallel processes in R that depend on:
your OS
whether you are running local or remote sessions
plan(sequential): default, will block
plan(multisession): parallel, no blocking
(plan(future.batchtools::batchtools_slurm))
(plan(future.callr::callr, workers = 4))
More to come
Workers
Remember, R resources are finite
As a rule of thumb, you don’t want to call more resources than you have
Code
parallel::detectCores()
[1] 16
Workers
in future, workers are basically the number of cores you want to use for parallel processing
-globals is an argument for future(). By default, it is set to TRUE - Alternatively, it could be a character vector including only those globals you want the future() call to have access to
packages is an argument for future(). By default, it is set to NULL
Alternatively, it could be a character vector including only those packages you want to import into the parallel calls
Useful when working with package conflicts, remote clusters
furrr: future + purrr
The goal of furrr is to combine purrr’s family of mapping functions with future’s parallel processing capabilities. The result is near drop in replacements for purrr functions such as map() and map2_dbl(), which can be replaced with their furrr equivalents of future_map() and future_map2_dbl() to map in parallel.
furrr
I personally use furrr frequently when I need to a bunch of stuff in parallel but not so much I find myself needing to reach for an HPC
Why? It works just like purrr functions but allows me to run them in parallel!
Code
plan(multisession, workers =2)1:10%>%future_map(rnorm, n =10, .options =furrr_options(seed =123)) %>%future_map_dbl(mean)
furrr
I also use furrr because it works just like future:
future_map(.x, .f, .options = furrr_options())
furrr_options() basically takes all the same arguments a typical future() call would take, including globals and packages
So with very little experience, you can shift an existing purrr workflow (or pieces of it) to parallel
Exercise
As a brief exercise, let’s revisit some of the latent growth models we ran last week:
The goal of furrr is to combine purrr’s family of mapping functions with future’s parallel processing capabilities. The result is near drop in replacements for purrr functions such as map() and map2_dbl(), which can be replaced with their furrr equivalents of future_map() and future_map2_dbl() to map in parallel.
Better alternative: don’t export large objects using furrr but save the output to a local environment that can be loaded in later
Next Week: Review
Next week, we’ll wrap up with a one hour “overview” highlighting big takeaways, reminders, etc. for the course
Then, everyone will have the chance to (optionally) share their favorite R hacks (hint: this is a good excuse / nudge to remember the bonus points you can get by submitting tidy tuesday style code)
Finally, we’ll have time to work on final projects
---title: "Week 9 Workbook"author: "Emorie D Beck"format: html: code-tools: true code-copy: true code-line-numbers: true code-link: true theme: united highlight-style: tango df-print: paged code-fold: show toc: true toc-float: true self-contained: trueeditor: visualeditor_options: chunk_output_type: console---# Week 9 - Git & Parallelization```{r, echo = T}pkg <-c("knitr", "psych", "palmerpenguins", "lavaan", "future", "plyr", "tidyverse", "furrr")pkg <- pkg[!pkg %in%rownames(installed.packages())]if(length(pkg) >0) map(pkg, install.packages)library(knitr)library(psych)library(lavaan)library(future)library(plyr)library(tidyverse)library(furrr) # note loading this last ONLY because it depends on tidyverse and will not mask it``````{r setup, include=FALSE}knitr::opts_chunk$set(echo =TRUE, message =FALSE, warning =FALSE,results ='show',fig.width =4, fig.height =4, fig.retina =3)options(htmltools.dir.version =FALSE , knitr.kable.NA ="")```# Outline1. Questions on Homework2. Git/GitHub3. Parallelization using `future`4. `furrr`## What and why use Git and GitHub?[Video](https://www.dropbox.com/s/r4gij79tw8dx1zv/doyle_why_code_git.mp4?dl=0) from Will Doyle, Professor at Vanderbilt University## What is **version control**?- [Version control](https://git-scm.com/book/en/v2/Getting-Started-About-Version-Control) is a "system that records changes to a file or set of files over time so that you can recall specific versions later"- Keeps records of changes, who made changes, and when those changes were made- You or collaborators take "snapshots" of a document at a particular point in time. Later on, you can recover any previous snapshot of the document.## How version control works:- Imagine you write a simple text file document that gives a recipe for yummy chocolate chip cookies and you save it as `cookies.txt`- Later on, you make changes to `cookies.txt` (e.g., add alternative baking time for people who like "soft and chewy" cookies)- When using version control to make these changes, you don't save entirely new version of `cookies.txt`; rather, you save the changes made relative to the previous version of `cookies.txt`## Why use Git and GitHub?Why use version control when you can just save new version of document?1. Saving entirely new document each time a change is made is very inefficient from a memory/storage perspective - When you save a new version of a document, much of the contents are the same as the previous version - Inefficient to devote space to saving multiple copies of the same content2. When document undergoes lots of changes -- especially a document that multiple people are collaborating on -- it's hard to keep track of so many different documents. Easy to end up with a situation like this:## Why use Git and GitHub?[](http://www.phdcomics.com/comics/archive.php?comicid=1531)*Credit: Jorge Chan (and also, lifted this example from Benjamin Skinner's [intro to Git/GitHub lecture](https://edquant.github.io/past/2020/spring/edh7916/lessons/intro.html))*## What is **Git**? (from git [website](https://git-scm.com/)) {.smaller}> "Git is a free and open source distributed version control system designed to handle everything from small to very large projects with speed and efficiency"- Git is a particular version control software created by *The Git Project* - [Git is free and open source software](https://git-scm.com/about/free-and-open-source), meaning that anyone can use, share, and modify the software - Although Microsoft owns Github (described) below, it thankfully does not own Git!- Git can be used by: - An individual/standalone developer - For collaborative projects, where multiple people collaborate on each file## What is a **Git repository**?- A Git repository is any project managed in Git- From [Git Handbook](https://guides.github.com/introduction/git-handbook/) by github.com: - A repository "encompasses the entire collection of files and folders associated with a project, along with each file's revision history" - Because git is a **distributed** version control system, "repositories are self-contained units and anyone who owns a copy of the repository can access the entire codebase and its history"- This course is a Git repository ([PSC290 FQ23 repository](https://github.com/emoriebeck/psc290-data-FQ23/))## What is a **Git repository**?- Local vs. remote git repository: - **Local** git repository: git repository for a project stored on your machine - **Remote** git repository: git repository for a project stored on the internet- Typically, a local git repository is connected to a remote git repository - You can make changes to local repository on your machine and then **push** those changes to the remote repository - Other collaborators can also make changes to their local repository, push them to the remote repository, and then you can **pull** these changes into your local repository## Private vs. public repositories- Public repositories: anyone can access the repository - e.g., [PSC290 FQ23](https://github.com/emoriebeck/psc290-data-FQ23/), the git repository we created to develop this course is a public repository because we want the public to benefit from this course- Private repositories: only those who have been granted access by a repository "administrator" can access the repository## What is **GitHub**?- [GitHub](https://github.com/) is the industry standard hosting site/service for Git repositories - Hosting services allow people/organizations to store files on the internet and make those files available to others- Microsoft acquired Github in 2018 for \$7.5 billion- Github is where **remote** git repositories live## Git Workflow {.smaller}Version control systems that save **differences**: - Prior to Git, "centralized version control systems" were the industry standard version control systems (From [Getting Started - About Version Control](https://git-scm.com/book/en/v2/Getting-Started-About-Version-Control)) - In these systems, a central server stored all the versions of a file and "clients" (e.g., a programmer working on a project on their local computer) could "check out" files from the central server - These centralized version control systems stored multiple versions of a file as "differences" - The below figure portrays version control systems that store data as changes relative to the base version of each file:## Git Workflow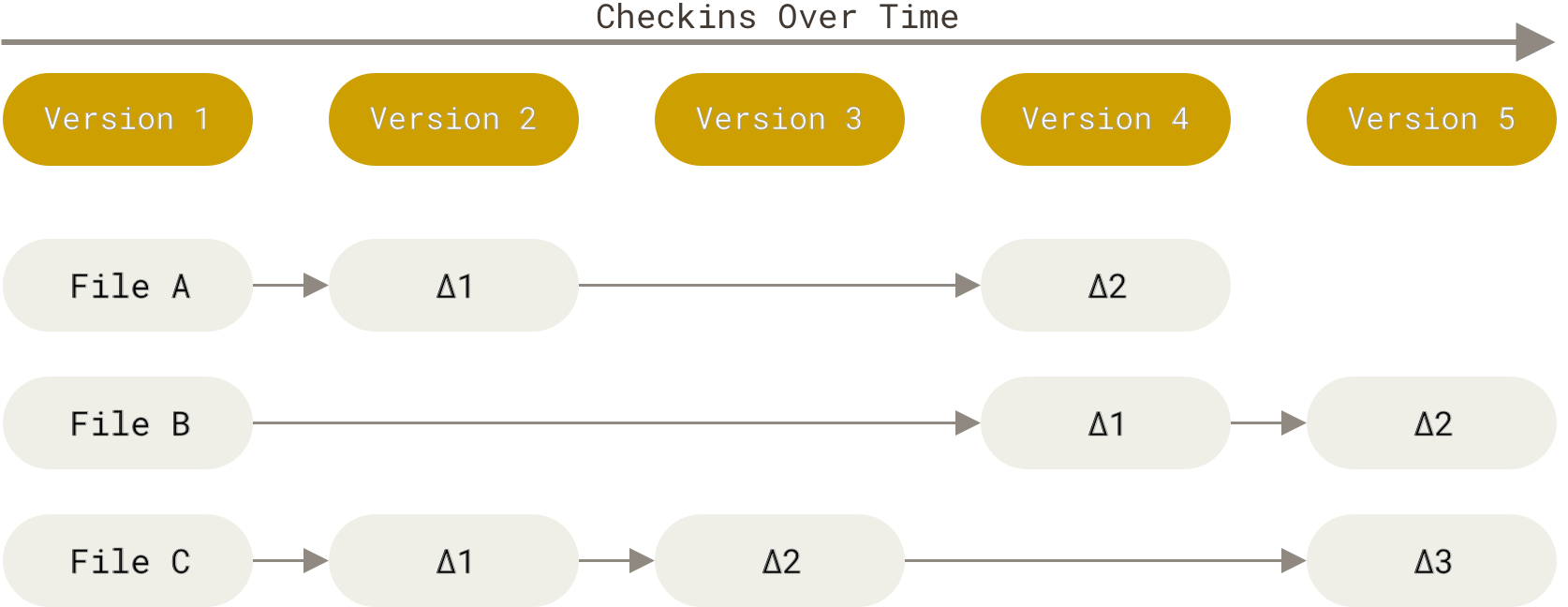*Credit: [Getting Started - What is Git](https://git-scm.com/book/en/v2/Getting-Started-What-is-Git%3F)*## Git WorkflowGit stores data as **snapshots** rather than *differences*:- Git doesn't think of data as differences relative to the base version of each file- Rather, Git thinks of data as "a series of snapshots of a miniature filesystem" or, said differently, a series of snapshots of all files in the repository- For files that have changed: - the "commit" will save lines that you have changed or added \[like "differences"\] - lines that have not changed will not be re-saved; because these lines have been saved in previous commit(s) that are linked to the current commit## Git Workflow- The below figure portrays storing data as a stream of snapshots over time: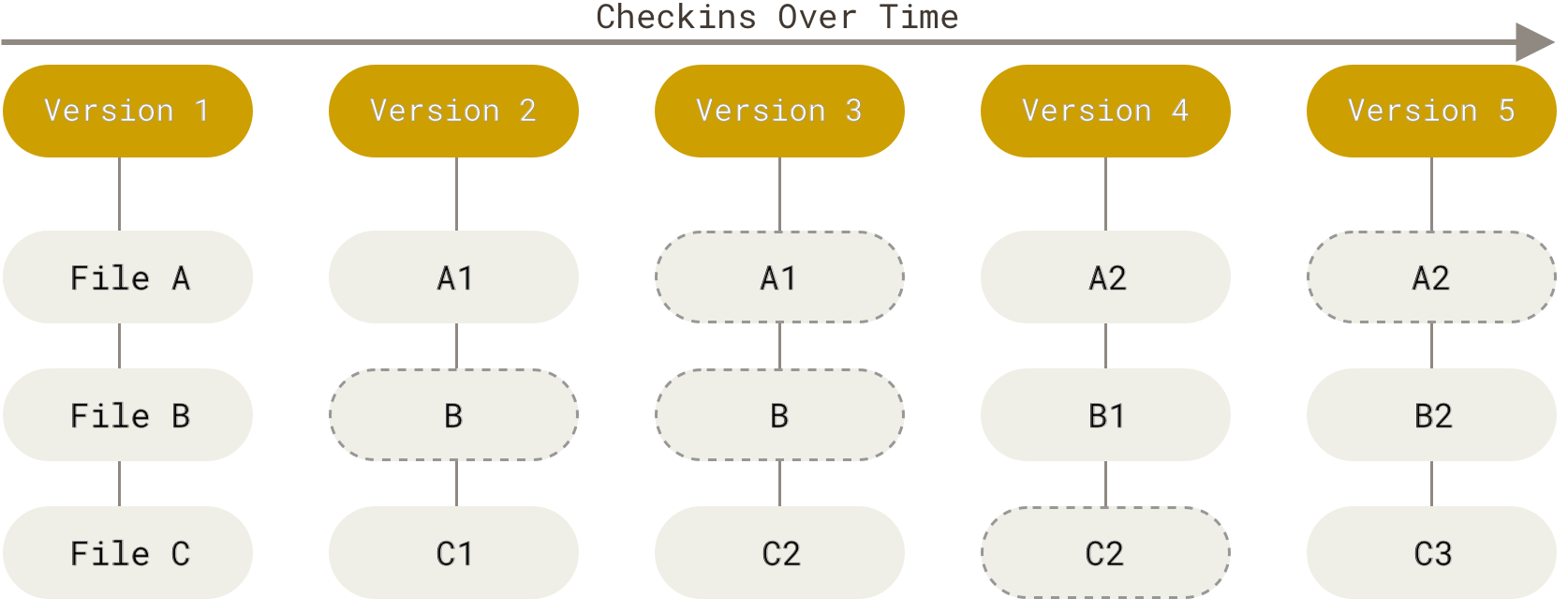*Credit: [Getting Started - What is Git](https://git-scm.com/book/en/v2/Getting-Started-What-is-Git%3F)*## What is a **commit**?- A **commit** is a snapshot of all files in the repository at a particular time- Example: Imagine you are working on a project (repository) that contains a dozen files - You change two files and make a commit - Git takes a snapshot of the full repository (all files) - Content that remains unchanged relative to the previous commit is stored vis-a-vis a link to the previous commit## Three components of a Git project<center>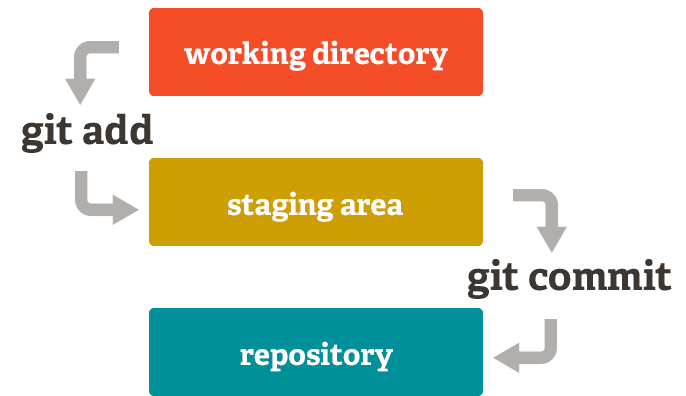{width="500px"}</center>*Credit: Lucas Maurer, [medium.com](https://medium.com/@lucasmaurer/git-gud-the-working-tree-staging-area-and-local-repo-a1f0f4822018)*## Three components of a Git project {.smaller}1. **Local working directory** (also called "working tree") - This is the area where all your work happens! You are writing Rmd files, debugging R scripts, adding and deleting files - These changes are made on your local machine!2. **Git index/staging area** (`git add <filename(s)>` command) - The staging area is the area between your *local working directory* and the *repository*, where you list changes you have made in the local working directory that you would like to commit to the repository3. **Repository** (`git commit` command) - This is the actual repository where Git permanently stores the changes you've made in the local working directory and added to the staging area## Git Workflow {.smaller}Hypothetical work flow to `cookies.txt`:- ***Add*** changes from *local working directory* to *staging area*- ***Commit*** changes from *staging area* to *repository*- Each **commit** to the repository is a different version of the file that represents a snapshot of the file at a particular time- Commits are made to **branches** in the repo - By default, a git repository comes with one main branch (typically called **main**) - But we can also create other branches (discussed more later)## Git Workflow- **Local** vs. **remote** repository - When you add a change to the *staging area* and then commit the change to your *repository*, this changes your *local repository* (i.e., on your computer) rather than your *remote repository* (i.e., on GitHub)- If you want to change the *remote repository* (typically named **origin**), you must ***push*** the change from your *local repository* to your *remote repository*- As seen below, each circle represents a **commit**. After you make commits on a branch in your *local repository* (i.e., **main**), you need to ***push*** them in order for the corresponding branch on the *remote repository* (i.e., **origin/main**) to be up-to-date with your changes.## GitHub Desktop- Practically, in this class, I'm going to show you how to use GitHub Desktop, which is a GUI (graphical user interface) for managing git repositories and commits.- Relative to the command line, using a GUI means you're ready to be "up and running with git immediately and don't have to learn bash syntax## Exercise: Setting Up GitHub Desktop- Rather than stepping through in the slides, I'm going to have each of you navigate to this link: <https://docs.github.com/en/desktop/overview/getting-started-with-github-desktop>.- Follow it to the end of Part 1 (Installing and authenticating) and then pause- Raise your hand if you need help- If you don't already have a GitHub account and don't want to set one up, work with someone around you## The basic workflow {.smaller}### First time1. **Clone** the repository that you want to work on from GitHub onto your local machine2. Work on the files/scripts, e.g., `penguins.R`3. Next, you will **commit** your changes and include an informative message, e.g. "Plot distribution of flipper length"4. Then, you will **push** your changes to the remote repository### Subsequent times1. **Pull** any changes from the remote repository that your collaborators might have made2. Repeat steps 2-4 above## Cloning```{=html}<div> <center> <video width="70%" height="60%" controls muted> <source src="https://github.com/walice/git-tutorial/raw/master/assets/cloning.mp4" type="video/mp4"> </video> </center></div>```## ExerciseThe repo [walice/git-tutorial](https://github.com/walice/git-tutorial) contains the `penguins.R` script, which works with data from the `palmerpenguins` library.*Credit: [5 Minute Git](https://github.com/walice/git-tutorial)*## Work on the files```{r include=FALSE, warning=FALSE}library(palmerpenguins)``````{r warning=FALSE, fig.align="center", fig.width=7, fig.height=5}ggplot(penguins, aes(x = bill_length_mm, y = bill_depth_mm, color = species)) +geom_point() +labs(title ="Penguin bills") +theme_classic()```## Staging your files## Commit your changes```{=html}<div> <center> <video width="70%" height="60%" controls muted> <source src="https://github.com/walice/git-tutorial/raw/master/assets/committing.mp4" type="video/mp4"> </video> </center></div>```## Commit your changes#### Use an informative commit message- (Not great) "Analyze data" `r emo::ji("disappointed")`- (Better) "Estimate logistic regression" `r emo::ji("tada")`#### Have a consistent style- Start with an action verb- Capitalize message#### Commits are *cheap*, use them often!## Push your changes```{=html}<div> <center> <video width="70%" height="60%" controls muted> <source src="https://github.com/walice/git-tutorial/raw/master/assets/pushing.mp4" type="video/mp4"> </video> </center></div>```## Why Use Git/Hub- Direct link to the Open Science Framework via "Add-ons," so you don't have to maintain / copy files multiple places- Easy collaboration with better tools for dealing with conflicts due to remotes- Easy to restore back to an earlier "snapshot"- Can directly link to files, data, etc. - by default, the links will be to the "main" - swap this out for "raw" and it will link to the raw file, which will open a raw text page for text files (including .csv) or download (including .docx, .pdf, etc.)# Parallel Processing in R## Guarding your resources- Computers have finite resources- A common source of issues in R is a cluttered environment - Objects you aren't using - Objects unrelated to whatever you're working on, etc.## Cleaning up your environment {.smaller}- The best ways to avoid issues due to a cluttered environment are: - Always start from a blank environment - Write scripts systematically. You shouldn't be skipping around and should be careful about overwriting objects - Save object(s), not your whole workspace to allow you to bring back in things you were working on previously - Use object names with clear patterns to allow you clean up your environment - `rm(list=ls()[grepl("RQ1", ls()])` - `rm(list=ls()[!ls() %in% c("df1", "df2")])` - Occasionally call `gc()` after cleaning up your environment## Guarding your resources- All of the above guard your **RAM**, but another cause of issues with resources is that you take full advantage of your computing power- Most modern computers have 8+ physical and virtual cores and powerful graphics cards- Together, these allow us to parallelize processes, which just means to do multiple different processes in parallel at the same time## Parallel Processing- You've likely used parallel processing in R before- Many packages, like `lavaan`, `lme4`, and any bootstrapping have an argument called `parallel`, with values like `TRUE`/`FALSE` or "fork"/"multisession"/"multicore"- This just means that they are using one of many available packages / tools to speed up the estmation of whatever your function is doing## Why use `future` for parallelization? {.smaller}- A Unifying Parallelization Framework in R for Everyone- Require only minimal changes to parallelize existing R code- "Write once, Parallelize anywhere- Same code regardless of operating system and parallel backend- Lower the bar to get started with parallelization- Fewer decisions for the developer to make- Stay with your favorite coding style- Worry-free: globals, packages, output, warnings, errors just work- Statistically sound: Built-in parallel random number generation (RNG)- Correctness and reproducibility of highest priority## Three atomic building blocksThere are three atomic building blocks that do everything we need:- `f <- future(expr)` : evaluates an expression via a future (non-blocking, if possible)- `rs <- resolved(f)` : `TRUE` if future is resolved, otherwise FALSE (non-blocking)- `v <- value(f)` : the value of the future expression `expr` (blocking until resolved)## ExampleTo break down what's happening, let's use a bad function, called `slow_sum()````{r}slow_sum <-function(x) { sum <-0for (kk inseq_along(x)) { sum <- sum + x[kk]Sys.sleep(0.1) # emulate 0.1 second cost per addition } sum}```*Credit: [future tutorial useR 2022](https://henrikbengtsson.github.io/future-tutorial-user2022)*## ExampleIf we then call, the following, it takes about 10 seconds```{r}x <-1:100v <-slow_sum(x)v#> [1] 5050```But we could do the same in future and see that time to evaluate has been cut in half:```{r}library(future)plan(multisession) # evaluate futures in parallelx <-1:100f <-future(slow_sum(x))v <-value(f)#> [1] 5050```## Anatomy of `future()` {.smaller}When we call:```{r}f <-future(slow_sum(x))```then:- a future is created, comprising: - the R expression slow_sum(x), - function slow_sum(), and - integer vector x- These future components are sent to a parallel worker, which starts evaluating the R expression- The `future()` function returns immediately a reference `f` to the future, and before the future evaluation is completed## Anatomy of `value()`When we call:```{r}v <-value(f)```then:- the future asks the worker if it's ready or not (using `resolved()` internally)- if it is not ready, then it waits until it's ready (blocking)- when ready, the results are collected from the worker- the value of the expression is returned## Benefits of future:- You can keep doing other things while your code runs in the background and then eventually check whether it's done using `resolved()` or `value()`- You can do multiple different futures at the same time## Benefits of future:When we run code normally, we experience blocking, which means that the next line can't run until the previous one is done.```{r}x_head <-head(x, 50)x_tail <-tail(x, 50)v1 <-slow_sum(x_head) ## ~5 secs (blocking)v2 <-slow_sum(x_tail) ## ~5 secs (blocking)v <- v1 + v2```But with future, we can parallelize and continue to run other things:```{r}f1 <-future(slow_sum(x_head)) ## ~5 secs (in parallel)f2 <-future(slow_sum(x_tail)) ## ~5 secs (in parallel)## Do other thingsz <-sd(x)v <-value(f1) +value(f2) ## ready after ~5 secs```## Setting up your future backendTo fully make use of future, you need to understand:- parallel backends- "workers"- globals\- packages## Parallel backends- There are multiple ways that you can run parallel processes in R that depend on: - your OS - whether you are running local or remote sessions1. `plan(sequential)`: default, will block2. `plan(multisession)`: parallel, no blocking3. (`plan(future.batchtools::batchtools_slurm)`)4. (`plan(future.callr::callr, workers = 4)`)5. More to come## Workers- Remember, `R` resources are finite- As a rule of thumb, you don't want to call more resources than you have```{r}parallel::detectCores()```## Workersin `future`, workers are basically the number of cores you want to use for parallel processing```{r, eval = F}plan(multisession, workers =8)nbrOfWorkers()#> [1] 8plan(multisession, workers =2)nbrOfWorkers()#> [1] 2```## Workersin `future`, workers are basically the number of cores you want to use for parallel processing```{r, eval = F}plan(multisession, workers =2)nbrOfWorkers()#> [1] 2f1 <-future(slow_sum(x_head))f2 <-future(slow_sum(x_tail))f3 <-future(slow_sum(1:200)) ## <= blocks hereresolved(f1)#> [1] TRUEresolved(f2)#> [1] TRUEresolved(f3)#> [1] FALSE```## Globals\-`globals` is an argument for `future()`. By default, it is set to `TRUE` - Alternatively, it could be a character vector including only those globals you want the `future()` call to have access to```{r, eval = F}x_head <-head(x, 50)x_tail <-tail(x, 50)plan(multisession, workers =2)f1 <-future(slow_sum(x_head), globals =c("slow_sum", "x_head"))f2 <-future(slow_sum(x_tail), globals =c("slow_sum", "x_head")) ## doesn't work```## Packages- `packages` is an argument for `future()`. By default, it is set to `NULL`- Alternatively, it could be a character vector including only those packages you want to import into the parallel calls - Useful when working with package conflicts, remote clusters# `furrr`: `future` + `purrr`> The goal of furrr is to combine purrr's family of mapping functions with future's parallel processing capabilities. The result is near drop in replacements for purrr functions such as map() and map2_dbl(), which can be replaced with their furrr equivalents of future_map() and future_map2_dbl() to map in parallel.## `furrr`- I personally use `furrr` frequently when I need to a bunch of stuff in parallel but not so much I find myself needing to reach for an HPC- Why? It works just like `purrr` functions but allows me to run them in parallel!```{r, eval = F}plan(multisession, workers =2)1:10%>%future_map(rnorm, n =10, .options =furrr_options(seed =123)) %>%future_map_dbl(mean)```## `furrr`- I also use `furrr` because it works just like future:- `future_map(.x, .f, .options = furrr_options())` - `furrr_options()` basically takes all the same arguments a typical `future()` call would take, including globals and packages- So with very little experience, you can shift an existing `purrr` workflow (or pieces of it) to parallel## ExerciseAs a brief exercise, let's revisit some of the latent growth models we ran last week:```{r}gsoep2_lavaan <-readRDS("week9-data.RDS")```## Exercise {.smaller}Below is the lavaan syntax we ran:```{r}mod <-' W1 =~ NA*I1_2005 + lambda1*I1_2005 + lambda2*I2_2005 + lambda3*I3_2005 W2 =~ NA*I1_2009 + lambda1*I1_2009 + lambda2*I2_2009 + lambda3*I3_2009 W3 =~ NA*I1_2013 + lambda1*I1_2013 + lambda2*I2_2013 + lambda3*I3_2013 i =~ 1*W1 + 1*W2 + 1*W3 s =~ -1*W1 + 0*W2 + 1*W3 ## intercepts I1_2005 ~ t1*1 I1_2009 ~ t2*1 I1_2013 ~ t3*1 I2_2005 ~ t1*1 I2_2009 ~ t2*1 I2_2013 ~ t3*1 I3_2005 ~ t1*1 I3_2009 ~ t2*1 I3_2013 ~ t3*1 ## correlated residuals across time I1_2005 ~~ I1_2009 + I1_2013 I1_2009 ~~ I1_2013 I2_2005 ~~ I2_2009 + I2_2013 I2_2009 ~~ I2_2013 I3_2005 ~~ I3_2009 + I3_2013 I3_2009 ~~ I3_2013 ## latent variable intercepts W1 ~ 0*1 W2 ~ 0*1 W3 ~ 0*1 #model constraints for effect coding ## loadings must average to 1 lambda1 == 3 - lambda2 - lambda3 ## means must average to 0 t1 == 0 - t2 - t3 '```## ExerciseAnd the function we ran:```{r}lavaan_fun <-function(d, trait){ m <-growth( mod , data = d , missing ="fiml" )# saveRDS(m, file = sprintf("results/models/%s.RDS", trait))return(m)}```## ExerciseBut instead of running the model using `map2()`, let's run it using `future_map2()````{r}start <-Sys.time()gsoep_nested2 <- gsoep2_lavaan %>%group_by(category, trait) %>%nest() %>%ungroup() %>%mutate(m =map2(data, trait, lavaan_fun))end <-Sys.time()print(end - start)# > Time difference of 4.413002 secs```## ExerciseIn this case, we're only saving a few seconds, but in the case having many more models or models that run longer, this can HUGELY add up```{r}start <-Sys.time()plan(multisession, workers = 5L)gsoep_nested2 <- gsoep2_lavaan %>%group_by(category, trait) %>%nest() %>%ungroup() %>%mutate(m =future_map2(data, trait, lavaan_fun))end <-Sys.time()print(end - start)# Time difference of 2.993128 secs```## Caution: Data transfer> The goal of furrr is to combine purrr's family of mapping functions with future's parallel processing capabilities. The result is near drop in replacements for purrr functions such as map() and map2_dbl(), which can be replaced with their furrr equivalents of future_map() and future_map2_dbl() to map in parallel.- Better alternative: don't export large objects using `furrr` but save the output to a local environment that can be loaded in later## Next Week: Review- Next week, we'll wrap up with a one hour "overview" highlighting big takeaways, reminders, etc. for the course- Then, everyone will have the chance to (optionally) share their favorite `R` hacks (hint: this is a good excuse / nudge to remember the bonus points you can get by submitting tidy tuesday style code)- Finally, we'll have time to work on final projects# AcknowledgmentsResources used to create this lecture:- https://anyone-can-cook.github.io/rclass2/- https://happygitwithr.com/- https://henrikbengtsson.github.io/future-tutorial-user2022- https://furrr.futureverse.org/- https://github.com/walice/git-tutorial/- https://edquant.github.io/edh7916/lessons/intro.html- https://www.codecademy.com/articles/f1-u3-git-setup





